

LINEとYahoo!の親会社であるZホールディングスが合併して以来、 昨年 3 月の日本 (ヤフー ジャパン) では、コミュニケーション プラットフォームの巨人と e コマースの巨人の合併がどのように新しい火花を生み出すかについて、あらゆる階層の人々が注目しました。
Z ホールディングスが設定した主な戦略目標は、データ ガバナンスの強化を優先することです。 実際、世界クラスの AI テクノロジー企業になることは、合併後の両当事者の共通の戦略的目標であり、高品質の利用可能なデータは、このビジョンに向けた重要な基本プロジェクトです。 特に、日本のLINEユーザー、日本のYahooユーザー、PayPayの3大エコシステムの統合後、ユーザー数は2億人に達しました。 新しいエコシステムを非常に大規模にサポートする方法については、Line と Yahoo Japan の最初の合同技術会議が今年 11 月に終了したばかりであり、データ技術と AI 技術が鍵であることがわかります。
ソーシャルプラットフォームを得意とし、海外多国展開の経験を持つLineと、eコマース、小売、金融に強い経験を持つYahoo Japanは、年次総会でそれぞれ異なる技術開発分野を披露しましたが、それぞれを補完しあう。 ラインは戦略的なプラットフォームベースの技術アーキテクチャ、特に AI アーキテクチャ、データ技術プラットフォーム、ブロックチェーン アーキテクチャの開発に重点を置いており、ヤフー ジャパンは AI アプリケーションと産業用 AI プラクティスの拡大に重点を置いています。 前者は AI 技術の物理的および将来の強化に焦点を当てており、後者は産業用 AI の領域と事業範囲の拡大に焦点を当てています。
LINEは現在、全世界で毎月約2億人のユーザーが利用しており、膨大なユーザーデータや行動データが蓄積されていることから、2019年には超大規模データプラットフォームのセルフサービスIU(Information Universe)を立ち上げました。 、その後 2020 年には、大規模な ML モデルの複数のクラスターをサポートするために、IU の上に Machine Learning Universe (MLU) 機械学習プラットフォームのレイヤーが開発されました。NLP モデル、コンピューター ビジョン モデル、レコメンデーション モデル、広告最適化モデル。
現在、IU は Line 内で 200 以上のサービスをサポートし、400 PB の HDFS データを保存し、40,000 以上の Hive テーブルを持ち、毎日 150,000 のジョブを実行しています。 Line の最高技術責任者である池部智宏氏は、「ビッグデータはストレージの大きな課題であるだけでなく、それを使用する際の大きな課題でもあります」と指摘しました。
新しい UI Data Platform 変換は、データ変更プロセスを視覚化するためのデータ系統機能を作成します
年次総会で、池辺智宏氏は、UI Web ポータルである UI 追跡に関するさらに発展した Web ベースのデータ ディレクトリ サービスを初めて発表しました。
この UI Web サイトでは、メタデータ収集メカニズム、データ プロファイリング メカニズム、法令順守要件を支援できるデータ検証ツールなど、多数の自動化メカニズムが提供されています。 さらに、IU は Apache Iceberg データ レイク テクノロジーを導入し、Spark ストリーミング ビッグ データ分析プラットフォームをバージョン 3.2 にアップグレードしました。
Web UI の最も重要な新機能は、2021 年 11 月にリリースされるデータ リネージ機能です。データ。 この問題を解決するには、データリネージメカニズムが必要です。
データ リネージ メカニズムを使用して、特定のデータの開始から今日までの開発パスを追跡し、データ変更プロセスをブラウザーのチャートで表示できます。
Line のデータ プラットフォーム部門のシニア プロダクト マネージャーである宇田川直人氏は、この内部データ ディレクトリは、データ検索、アクセス制御、メタデータ管理、探索的データ分析などを改善するために、すべてのデータ アクティビティをカバーする単一のエントリを提供すると述べています。 データ使用効率。
ただし、このようなデータ カタログの作成には 2 つの大きな課題があります。1 つはすべてのデータセットからメタデータを収集すること、もう 1 つはこれらのメタデータ間の関係をどのように提示するかです。 Line は、オープン ソースのディレクトリ サービス プロジェクトである Apache Atlas を使用して、さまざまなデータ ソースを接続します。 データ収集後、変化状況を把握するためのデータを定義し、各データの変化過程を視覚的に提示します。 これがデータ系統メカニズムです。 データ祖先マップのノードごとに、データ テーブルの紹介、タイムスタンプ、テーブル間の関係、PII (個人データを含む)、データ所有者、ユーザー ユニット、およびこのデータから生成された関連レポートを一覧表示できます。 、ユーザーリスト、各種リンクなど
ただし、UI には 40,000 の Hive テーブルがあり、毎日 150,000 のタスクが実行されます。 各タスクと各テーブルは、データ祖先マップ上のノードです。 設立から今日までのすべての変化と接続を追跡するには、非常に複雑で大規模なノード関連グラフが生成されます。
データ系統図の読みやすさを向上させるために、Line はいくつかの設計メカニズムを採用して、データ系統図の複雑さを簡素化しました。 Line は Atlas を使用して HIVe と Spark サーバーをシリアルに接続し、Atlas の通知メカニズムを使用してメタデータをプッシュおよび更新します。 ただし、毎日何十万ものタスクが UI で実行されるため、データ テーブルは数分間で何百回も変更されます。 そのため、Line は Atlas からの通知を Kafka を介して集約し、追跡の最小単位として 30 分を使用し、悪用されたデータベースで注文の追加や削除を繰り返すなど、30 分以内の変更を排除します。これにより、変更通知の 90% が大幅に削減されます。 . トランザクション モードをさらに比較することで、ユーザーにとって意味のない DDL 構文のトランザクション情報が除外され、ノイズが 95% 大幅に削減されます。
また、データ系統データベースへの重要でないデータノードの登録を排除したことで、ノード数が90%も大幅に削減され、30,000の不要なタスクも排除されました。 フィルタリングとフィルタリングのレイヤー上のこれらのレイヤーにより、Line UI Web データ カタログによって提供されるデータ リネージは、複雑さを軽減して処理でき、ノット ユニットのようなフィールドを使用して相関分析図に拡張することもできます。
Line はまた、データの血統を出生から現在までデフォルトで拡張できる対話型インターフェースも提供します。
統計によると、2022 年 5 月現在、79 の部門と部門がこの機能を使用しており、ETL、データ管理、データ分析などの機能に日常的に使用されています。 ETL チームは、データ テーブルのメンテナンスの範囲を確認します。特に、データ テーブルを削除または変更する場合は、より快適に感じることができます。多くのユーザーは、さまざまなデータ エラーの根本原因を見つけるために、日常のデータ リネージを使用することがよくあります。
「データ間の関係を把握できれば、膨大なデータを管理して再利用効率を向上させる方法を簡単に知ることができ、このデータをセキュリティとガバナンスの観点から使用することができます」と池部智宏氏は述べています。 UI だけでなく、MLU プラットフォームでも、同じリネージ テクノロジを使用して、モデルがトレーニングに使用するデータと、トレーニングでどのように使用されるかを追跡できます。
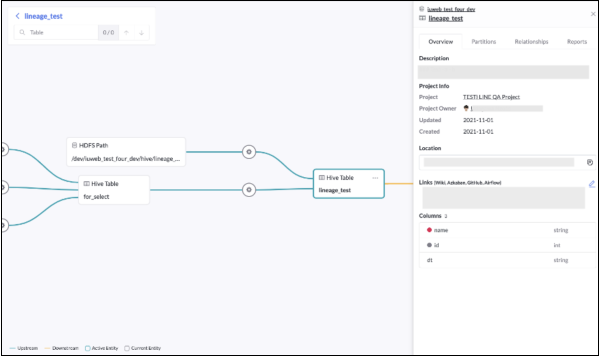
Web UI のデータ リネージ機能は、誕生から現在までのデータ リネージ、つまりデータ リネージを表示できます。 デフォルトでは、重要なノードの 3 つのレイヤーが展開されます。 ユーザーは自分で画面をズームインまたはズームアウトするか、任意のデータ列の位置をターゲットにしてから、データ系列相関図の次の 3 つのレイヤーを展開できます。画像ソース/ライン
MLU オンライン機械学習プラットフォームが新しい共同学習アーキテクチャを導入
UI データ プラットフォームが大幅に変更されただけでなく、Line の MLU 機械学習プラットフォームも新しいアーキテクチャとトレーニング モデルを採用しました。 池辺智宏氏によると、Lineは今秋、ステッカーレコメンデーションに新しい機械学習トレーニングアーキテクチャのセットを導入し、「プライバシーとユーザーの利便性を考慮しながら、爆発的な機能を処理してモデルを構築できます。つまり、連合学習(Federated Learning)とプライバシーの違い(差分)プライバシー)。
共同学習メカニズムを通じて、モデルのトレーニングはユーザーのローカル アプリケーションで完了し、差分プライバシー アーキテクチャ (差分プライバシー) を使用してモデルにノイズを追加し、元のモデル データを押し戻さないようにし、ユーザーなしでモデルの機能を返します。データをバックエンドに送信してグローバル レコメンデーション モデルを更新し、新しいモデルをユーザー アプリケーションに配布し、ローカル ログを使用してよりパーソナライズされたレコメンデーション シーケンスを生成します。
ヤフージャパンのCTOである小久保正彦氏は、両社が共同で巨大なユーザーと爆発的なデータを蓄積しており、成長は加速するだけだと指摘した。 成長し続けるためには、トラフィックとデータの急増に対応するための柔軟なプラットフォームの構築など、多くの技術的課題を解決する必要があります。 また、高度な AI 技術の導入を拡大または加速する必要もあります。 また、信頼を構築するためには、情報セキュリティとプライバシー保護のための信頼できるフレームワークを作成する必要があります。
これら 3 つの主要な課題は、まさに Line データ プラットフォームと AI アーキテクチャの新しい変革が解決しなければならないものです。


「極端なインターネットの第一人者。熱心な作家。思想家。食品の先駆者。Twitterの学者。ハードコアなアルコール擁護者。」





